ABBYY FineReader for ScanSnap의 OCR (광학 문자 인식) 기능
이 단원에서는 ABBYY FineReader for ScanSnap의 OCR 기능에 대해서 설명하고 있습니다.
ABBYY FineReader for ScanSnap의 개요
ABBYY FineReader for ScanSnap은 ScanSnap의 전용 애플리케이션입니다. 본 프로그램은 ScanSnap에서 작성된 PDF 파일에서 텍스트 인식을 실행할 수 있습니다. Adobe Acrobat 또는 기타 애플리케이션에서 작성된 파일의 텍스트 인식은 실행할 수 없습니다.
OCR 기능의 특성
OCR 기능의 특성은 다음과 같습니다. 텍스트 인식을 실행하기 전 다음 가이드 라인에 따라 변환에 적합한 문서인지 확인해 주십시오.
| 애플리케이션 | 텍스트 인식에 적합한 문서 | 텍스트 인식에 적합하지 않은 문서 |
|---|---|---|
| ABBYY Scan to Word | 단일 또는 더블 열로 구성된 단순한 레이아웃의 문서 |
도표, 테이블, 텍스트 등의 복잡한 레이아웃을 가진 문서(예. 브로슈어, 잡지 및 신문) |
| ABBYY Scan to Excel(R) | 모든 테두리가 외부 프레임에 연결되는 단순 테이블이 있는 문서. |
다음을 포함하는 문서
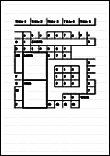 |
| ABBYY Scan to PowerPoint(R) | 흰색 또는 단일색의 배경에 텍스트 및 단순한 도표/테이블을 포함한 문서 |
 |
원본 문서대로 재현할 수 없는 파라미터
다음 항목은 원본 문서 그대로 재현할 수 없습니다. Word, Excel, 또는 PowerPoint에서 텍스트 인식의 결과를 확인하고 필요할 경우 데이터를 편집할 것을 권장합니다.
- 글꼴 및 문자 크기
- 문자 간격 및 선 간격
- 밑줄, 굵은 문자 및 이탤릭체 문자
- 윗첨자/아랫첨자
올바르게 인식할 수 없는 문서
다음 타입의 문서는 올바로 인식되지 않을 수 있습니다. 이러한 경우 [칼라 모드 선택]을 [칼라]로 변경하거나 해상도 (이미지 화질)를 올려 스캔함으로서 인식 가능할 수 있습니다.
- 손으로 직접 적은 문서
- 너무 작은 문자를 포함한 텍스트 (폰트 크기가10 미만)
- 비뚤어진 문서
- 지정된 언어 이외의 언어로 된 문서
- 불균일한 색상의 배경 위에 문자가 있는 문서
예: 음영 문자 - 장식 문자가 많이 포함된 문서
예: 장식 문자 (엠보스/아웃라인) - 무늬가 있는 배경에 문자가 있는 문서
예: 그림과 도표에 겹치는 문자 - 많은 문자가 밑줄 또는 테두리를 포함하는 문서
- 복잡한 레이아웃과 이미지 노이즈가 많은 문서
(이러한 문서를 변환할 때에는 인식 처리에 시간이 걸립니다.)
기타 고려사항
- 문서를 Excel 파일로 변환할 때 인식 결과가 65,536행을 초과하면 그 이상의 결과는 출력되지 않습니다.
- 문서를 Excel 파일로 변환할 경우 문서 전체의 레이아웃 정보, 도면과 그래프 및 높이/너비의 정보는 재현할 수 없습니다. 표와 문자만 재현됩니다.
- PowerPoint 문서로 변환할 경우 배경색 및 모형은 재현되지 않습니다.
- 문서의 앞뒤 또는 가로 방향이 바르게 변환되지 않을 수 있습니다. 스캔한 이미지를 올바른 방향으로 회전하기을 사용하거나 문서를 올바른 방향으로 올려 놓습니다.
- 블리드 스루 감소가 유효로 되면 인식률이 낮아질 수 있습니다. 그 경우 다음과 같은 절차로 무효로 하십시오.
키보드의 [control] 키를 누른 상태에서 Dock에서 ScanSnap Manager 아이콘
 을 클릭하고 ScanSnap Manager 메뉴에서 [설정] → [스캔 중] 탭 → [옵션] 버튼을 클릭하여 [스캔 모드 옵션] 창을 표시합니다. 그런 다음 [스캔 모드 옵션] 확인란의 선택을 해제합니다(SV600의 경우 [블리드 스루를 줄입니다] 확인란은 [스캔 모드 옵션] 창의 [이미지 화질] 탭에 있습니다).
을 클릭하고 ScanSnap Manager 메뉴에서 [설정] → [스캔 중] 탭 → [옵션] 버튼을 클릭하여 [스캔 모드 옵션] 창을 표시합니다. 그런 다음 [스캔 모드 옵션] 확인란의 선택을 해제합니다(SV600의 경우 [블리드 스루를 줄입니다] 확인란은 [스캔 모드 옵션] 창의 [이미지 화질] 탭에 있습니다).