ScanSnap 的 ABBYY FineReader 光學字元辨識 (OCR) 功能。
本節說明關於使用 ScanSnap 時,ABBYY FineReader 的 OCR 功能。
ABBYY FineReader for ScanSnap 概要
ABBYY FineReader for ScanSnap 是 ScanSnap 專用的應用程式。此程式只能對使用 ScanSnap 作成的 PDF 檔案執行文字辨識。無法對 Adobe Acrobat 或其他應用程式作成的 PDF 檔案執行文字辨識。
OCR 功能的特色
OCR 功能擁有以下特性。執行文字辨識前,請參閱以下準則檢查文件是否適合文件辨識:
| 應用程式 | 適合文件辨識 | 不適合文件辨識 |
|---|---|---|
| ABBYY Scan to Word | 含有單欄或雙欄版面簡單的文件 |
含有圖表、表格和文字等版面複雜的文件 (例如小冊子、雜誌和報紙) |
| ABBYY Scan to Excel(R) | 文件的表格簡單,各框線皆與外框相連。 |
包含以下項目的文件:
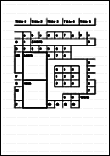 |
| ABBYY Scan to PowerPoint(R) | 背景為白色或單一淡色,而且包含文字或簡單圖表 / 表格的文件。 |
 |
無法按照原始文件重現的參數
以下參數可能無法按照原稿還原。建議在 Word、Excel 或 PowerPoint 中檢查轉換結果,並視需要編輯資料:
- 字元的字型與大小
- 字元間距與行距
- 底線、粗體、斜體字元
- 上標/下標
無法正確辨識的文件
可能無法正確辨識以下類型的文件。變更色彩模式或提高解析度,均可能獲得較佳的文字辨識效果。
- 含手寫字元的文件
- 含有小字元的文件 (小於字型大小 10)
- 歪斜的文件
- 書寫語言並非指定語言的文件
- 字元背景顏色不均的文件
圖例: 加有網底的字元 - 含有許多裝飾字元的文件
圖例: 裝飾字元 (浮凸/框線) - 字元後含圖樣背景的文件
圖例: 字元與圖片和圖表重疊 - 含有許多字元與底線或邊框相連的文件
- 版面複雜的文件和有大量影像雜訊的文件
(對這類文件處理文字辨識時,可能需要花費較長的時間)
其他注意事項
- 轉換比 Word 所允許最大尺寸的文件時,可使用 Word 可用的最大紙張尺寸。
- 將文件轉換為 Excel 檔案時,如果辨識結果超過 65,536 行,則不會儲存超過此限的辨識結果。
- 將文件轉換為 Excel 檔案時,系統不會複製整份文件、圖表、圖片和表格長度/寬度等版面資訊。只會重現表格及字元。
- 轉換後的 PowerPoint 文件不會含有原來的背景顏色和圖樣。
- 無法正確辨識上下顛倒或橫向放置的文件。使用 將掃描影像旋轉至正確方向,或將文件以正確方向放置。
- 若啟用了減少透印功能,辨識率可能會下降。在此情況下,請按照以下程序停用此功能。
在位於工作列右端的通知區域中的 ScanSnap Manager 圖示
 上按一下滑鼠右鍵,並從「右鍵功能表」中,按一下 [Scan 按鈕之設定] → [掃描中] 標籤 → [選項] 按鈕,以顯示 [掃描模式選項] 視窗。然後,清除 [掃描模式選項] 核取方塊 (使用 SV600 時,[減少透印] 核取方塊位於 [掃描模式選項] 視窗的 [畫質] 標籤中)。
上按一下滑鼠右鍵,並從「右鍵功能表」中,按一下 [Scan 按鈕之設定] → [掃描中] 標籤 → [選項] 按鈕,以顯示 [掃描模式選項] 視窗。然後,清除 [掃描模式選項] 核取方塊 (使用 SV600 時,[減少透印] 核取方塊位於 [掃描模式選項] 視窗的 [畫質] 標籤中)。