本網站專為搭配 ScanSnap Home 2.xx 使用而設計。
若您使用的是 ScanSnap Home 3.0 或更新的版本,請參閱 此處。
ABBYY FineReader for ScanSnap 的 OCR 功能
ABBYY FineReader for ScanSnap 是 ScanSnap 專用的應用程式。OCR 功能可用來針對 ScanSnap 所掃描文件的 PDF 格式影像中的文字資訊執行文字辨識,並將該影像轉換為 Word、Excel 或 PowerPoint 檔案。
本章節在說明用 ABBYY FineReader for ScanSnap 轉換影像中的文字資訊之功能特色和注意事項。
ABBYY FineReader for ScanSnap 的 OCR 功能特色
ABBYY FineReader for ScanSnap 的 OCR 功能具有以下特性。在轉換影像之前,請檢查要轉換的影像中的內容。
用於轉換的應用程式 |
適合轉換的文件 |
不適合轉換的文件 |
|---|---|---|
Scan to Word |
單欄或雙欄等版面簡單的文件。  |
由以下項目組合而成且版面複雜的文件 (例如小冊子、雜誌和報紙):
 |
Scan to Excel |
簡單的表格,亦即各框線皆與外框相連的表格。  |
包含以下項目的文件:
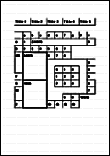 |
Scan to PowerPoint(R) |
背景為白色或單一淡色,僅含字元或簡單圖表或表格的文件。  |
 |
無法按照原稿還原的參數
以下參數可能無法按照原稿還原。使用 Word、Excel 或 PowerPoint 檢查轉換後的檔案,並視需要編輯。
字元的字型與大小
字元間距與行距
底線、粗體、斜體字元
上標/下標
可能無法正確辨識的文件和字元
對於以下類型的文件和字元可能無法正確辨識。
如果變更色彩模式或在 個人設定 的設定中提高畫質來掃描,或許能辨識。
含手寫字元的文件
小於 10 pt 的小字元文件
歪斜的文件
書寫語言並非指定語言的文件
字元背景顏色不均的文件,如加有網底的字元
含有許多裝飾字元的文件,如浮凸或框線的字元
字元後含圖樣背景的文件,如與圖片和圖表重疊的字元
含有許多字元與底線或邊框相連的文件
版面複雜的文件和有影像雜訊的文件 (對這類文件處理文字辨識時,可能需要花費較長的時間)
其他注意事項
將大於紙張大小的文件轉換為 Word 檔時,可能會轉換為 Word 可允許的最大紙張大小的檔案。
文件轉換為 Excel 檔時,若辨視結果超過 65536 行,則不會儲存第 65536 行之後的行數。
文件轉換為 Excel 檔時,不會還原整份文件的版面、圖表、相片及表格的長度和寬度。僅還原字元及表格。
文件轉換為 PowerPoint 檔時,不會還原背景色及樣式。
如果掃描文件上下顛倒或偏側,則無法正確轉換影像。在 [詳細設定] 視窗 中設定 [掃描] 中的 [旋轉],或正確載入文件,然後掃描文件。
已啟用減少透印功能時,文字辨識率可能降低。若要停用減少透印功能,在個人設定的設定中,清除勾選 [掃描選項] 視窗中的 [減少透印] 核取方塊。
已啟用減少透印功能時,文字辨識率可能降低。若要停用減少透印功能,在個人設定的設定中,清除勾選 [掃描選項] 視窗的 [畫質] 標籤中的 [減少透印] 核取方塊。