OCR-Funktion (Texterkennung) des ABBYY FineReader for ScanSnap
ABBYY FineReader for ScanSnap wurde exklusiv für die Verwendung mit dem ScanSnap konzipiert. Damit können Sie eine Texterkennung der Textinformationen in einem Bild im PDF-Format ausführen, das von einem mit dem ScanSnap gescannten Dokument stammt, und das Bild in eine Word-, Excel- oder PowerPoint-Datei konvertieren.
In diesem Abschnitt werden die Merkmale der Funktion zum Konvertieren der Textinformationen in einem Bild mit ABBYY FineReader for ScanSnap und Hinweise dazu erläutert.
Merkmale der OCR-Funktion (Texterkennung) des ABBYY FineReader for ScanSnap
Die Texterkennungsfunktion von ABBYY FineReader for ScanSnap weist folgende Merkmale auf. Überprüfen Sie vor dem Konvertieren eines Bilds die Inhalte darin.
Anwendung für Konvertierung |
Für Konvertierung geeignete Dokumente |
Für Konvertierung nicht geeignete Dokumente |
|---|---|---|
Scan to Word |
Dokumente mit einem einfachen Seitenaufbau mit einer oder zwei Spalten pro Seite.  |
Dokumente wie Broschüren, Zeitschriften oder Zeitungen mit einem komplexen Seitenaufbau, wie z. B.:
 |
Scan to Excel |
Dokumente mit einfachen Tabellen, bei der alle Rahmen Kontakt mit dem äußeren Rand haben.  |
Dokumente mit folgenden Inhalten:
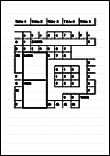 |
Scan to PowerPoint(R) |
Textdokumente mit einfachen Graphen oder Tabellen mit weißem oder hellem einfarbigen Hintergrund.  |
 |
Parameter, die sich nicht wie im Originaldokument reproduzieren lassen
Folgende Parameter werden unter Umständen nicht wie im Originaldokument reproduziert. Überprüfen Sie die konvertierten Dateien mit Word, Excel oder PowerPoint und bearbeiten Sie die gegebenenfalls.
Schriftart und -größe
Zeichen- und Zeilenabstand
Unterstrichene, fettgedruckte und kursive Zeichen
Hoch- oder tiefgestellte Zeichen
Dokumente und Zeichen, die möglicherweise nicht korrekt erkannt werden
Bei folgenden Dokumenten und Zeichen kann die Texterkennung unter Umständen nicht erfolgreich ausgeführt werden.
Dokumente mit handschriftlichen Zeichen
Dokumente mit kleinen Zeichen von unter 10 pt.
Schräge oder verzerrte Dokumente
Dokumente in anderen als der angegebenen Sprache
Dokumente mit Texten auf ungleichmäßig gefärbtem Hintergrund wie schattierten Zeichen
Dokumente mit vielen verzierten Zeichen wie geprägten Zeichen oder Zeichen mit Umrissen
Dokumente mit Zeichen auf einem gemusterten Hintergrund wie mit Abbildungen oder Diagrammen überlappende Zeichen
Dokumente mit vielen an Unterstriche oder feste Begrenzungslinien grenzenden Zeichen
Dokumente mit komplexem Layout oder mit Bildstörungen (Die Texterkennung solcher Dokumente kann längere Zeit in Anspruch nehmen.)
Sonstige Hinweise
Wird ein Dokument mit großer Papiergröße in eine Word-Datei konvertiert, wird es eventuell in eine Datei mit der für Word maximal zulässigen Papiergröße konvertiert.
Wird ein Dokument in eine Excel-Datei konvertiert und die Erkennungsergebnisse übersteigen 65536 Zeilen, werden die Zeilen nach der 65536. Zeile nicht gespeichert.
Wird ein Dokument in eine Excel-Datei konvertiert, wird das Layout des gesamten Dokuments wie Diagramme, Graphen sowie Höhe und Breite der Tabellen nicht reproduziert. Nur Tabellen und Text werden reproduziert.
Wird ein Dokument in eine PowerPoint-Datei konvertiert, werden die Hintergrundfarben und -muster nicht reproduziert.
Wenn ein Dokument seitlich gedreht wurde oder falsch herum liegt, kann das gescannte Bild nicht korrekt in die gewünschte Datei konvertiert werden. Lesen Sie unter Drehen einer Seite um 90 oder 180 Grad nach und korrigieren Sie die Ausrichtung des gescannten Bildes, bevor Sie es konvertieren.