此网站设计用于ScanSnap Home 2.xx。
如果您正在使用ScanSnap Home 3.0或更高版本,请参阅此处。
ABBYY FineReader for ScanSnap的OCR功能
ABBYY FineReader for ScanSnap为只对ScanSnap使用的应用程序。OCR功能可用于执行通过ScanSnap扫描的PDF格式文档中的图像中文本信息的文本识别,并将图像转换为Word、Excel或PowerPoint文件。
本节说明通过ABBYY FineReader for ScanSnap转换图像中的文本信息的特色及该功能的注意事项。
ABBYY FineReader for ScanSnap的OCR功能的特色
ABBYY FineReader for ScanSnap的OCR功能具有以下特色。在转换图像前,检查要转换的图像中的内容。
用于转换的应用程序 |
适合转换的文档 |
不适合转换的文档 |
|---|---|---|
Scan to Word |
使用只有一、二栏的简单的页面布局的文档。  |
使用含以下项目的复杂页面布局创建的文档,如小册子、杂志和报纸:
 |
Scan to Excel |
简单的表格,其中每条边线连接到外部边框。  |
包含以下项目的文档:
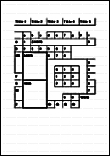 |
Scan to PowerPoint(R) |
只含有字符和简单图形或表格、背景为白色或浅淡单色的文档。  |
 |
无法重现为与原始文档相同的参数
下面的参数可能无法被重现为与原始文档中的相同。通过Word、Excel或PowerPoint检查转换的文件并根据需要进行编辑。
字符字体和大小
字符和行距
下划线、粗体、斜体
上标/下标字符
可能无法正确识别的文档和字符
以下类型的文档和字符可能不会被正确识别。
如果扫描时在个人设置的设置中更改色彩模式或提高图像画质,则可能会被识别。
含有手写字符的文档
包含小于10 pt.小字符的文档
倾斜的文档
以非指定语言写成的文档
在不均匀色彩的背景上写有字符(如阴影字符)的文档。
带有很多装饰字符(如压花或有边框的字符)的文档
字符带有花纹背景(如与插图和图表重叠的字符)的文档
含有很多下划线或粗体字符的文档
带复杂布局的文档和带图像噪点的文档(对这类文档进行文本识别处理可能会花费额外的时间。)
其他注意事项
当转换大于纸张大小的文档为Word文件时,可能被转换为Word所允许的最大纸张大小的文件。
转换文档为Excel文件时,如识别结果超过65536行,将不保存第65536行以后的内容。
转换文档为Excel文件时,将无法重现整个文档的布局、图标、图形、表格的高度和宽度。只能重现表格和字符。
转换文档为PowerPoint文件时,将无法重现背景颜色和底纹。
如果上下颠倒或斜向扫描文档,可能无法正确转换图像。在[详细设置]窗口中的[扫描]中设置[旋转]或正确放置文档,然后扫描文档。
当启用减少背面透过功能时,文本识别率可能会下降。若要禁用减少背面透过功能,请在个人设置的设置中的[扫描选项]窗口中取消勾选[减少背面透过]复选框。
当启用减少背面透过功能时,文本识别率可能会下降。若要禁用减少背面透过功能,请在个人设置的设置中[扫描选项]窗口中的[图像画质]选项卡中取消勾选[减少背面透过]复选框。