FAQ(よくあるご質問) 回答
販売終了製品
帳票認識に関するご質問
| Q1 | ひな型と認識する帳票の解像度は異なっていても構いませんか? |
| A1 | DynaEye Proでは、書式定義に使用したひな型の解像度と、その書式定義を使って帳票認識を行なう帳票の解像度は一致している必要があります。 なお、書式定義の解像度を変えることはできません。ひな型イメージから取り直す必要があります。 |
| Q2 | フィールド情報ダイアログで「知識処理」を指定しているのですが、知識処理の効果が感じられません。 |
| A2 | 定義のメニューから知識処理情報を選択してダイアログを開き、知識処理の内容と処理したいフィールド名を設定してください。DynaEye V1.1では、フィールド情報ダイアログの「知識処理情報」は、字種を限定するための設定情報であり、ここの設定だけでは知識処理が機能しません。 |
| Q3 | 認識率がとても悪いんですが? | ||||||||||||
| A3 | 下記に該当しないかご確認ください。
|
||||||||||||
| Q4 | 帳票認識に失敗して、×マークが付いてしまうのですが。 |
| A4 | 大きく分けると、二種類の原因が考えられます。
前者に関しては、
などが考えられます。これらは適切な設定を行なうことで、読み取り可能です。 後者に関しては、
などが考えられます。こちらは、DynaEye Proの読み取り対象とするのが難しい書式です。帳票のデザインを再検討してください。 |
| Q5 | 手動でアンカーパターンを設定していると、帳票リジェクトがいつも発生するのですが? |
| A5 | 手動でアンカーパターンを指定する場合、繰り返し同じようなパターンが出現する部分を設定していませんか?例えば、「住所・氏名」という文字の上にアンカーを設定していて、そのすぐ下に同じ文字があるようなケースです。DynaEyeは帳票認識の際に用紙の歪みを吸収する関係上、同じパターンがすぐ近くにあると誤る可能性があります。アンカーパターンを設定する場合は、類似したパターンがない場所を選んでください。 |
| Q6 | モノクロ形式で入力しているのですが、どうしても帳票認識に失敗してしまいます。 |
| A6 | モノクロ形式でも、画像の階調を表現するために、中間調処理やディザ処理を行なうことができるスキャナがあります。DynaEye Proの帳票認識では階調表現をしたイメージを扱うことはできません。スキャナの設定で、「中間調」「ディザ」「ハーフトーン」といった指定(お使いのスキャナによって異なります)は行なわないでください。 |
| Q7 | 手書きのひらがなは認識できないのですか? |
| A7 | 手書きひらがなは、手書き漢字(日本語)の中に含まれており、認識可能です。手書き漢字(日本語)として、JIS第一水準漢字・JIS第二水準漢字(一部)の他に、カタカナ、ひらがな、数字、英字(大文字)を読み取ることができます。 |
| Q8 | データチェック機能を使って、2箇所以上の項目を関連させてチェックを行なうことができますか?たとえば、「4月31日」と記入された場合はエラーとするなど。 |
| A8 | 可能です。例えば、"jdate(4,19,[月],[日])"のようにデータチェック式を記述すると、「平成19年」を前提として、「月」フィールドと「日」フィールドを連携したチェックができます。 |
| Q9 | 帳票認識を実行すると、インストールフォルダに"error1.log"、"error2.log"、... というファイルが作成されますが、何かエラーが発生しているのでしょうか?V5.0からは、作業フォルダの下に出力されるようになりました。 |
| A9 | 帳票認識等の実行時にログ(実行経過)を記録して"error?.log"(?は一桁の数字、1から5まで)というファイル名でインストールフォルダに保存していました。このファイルは、正常に動作していても作成されますので、特に気にする必要はありません。なお、DynaEye標準アプリケーション、アプリケーションプログラムインターフェースのいずれを使用しても出力されます。 V3.0からは"DynaEye1.log"、"DynaEye2.log"、...という名前に変更されています。 V5.0からはインストール時に指定した作業フォルダの配下に出力されるように変更されています。 |
| Q10 | 活字ANKSフィールドにMS明朝やMSゴシックで印字しているのに、読み誤りが多いのですが? |
| A10 | 2バイトコード文字(いわゆる「全角」)で印字していませんか?認識可能なMS明朝・MSゴシックの印字は、いわゆる「半角」(1バイトコード文字)印字だけです。 |
| Q11 | 帳票ID識別では、登録していないIDを読み取った場合、エラーになり処理が止まりますか? |
| A11 | 書式定義にないIDの帳票を認識した時はエラー(認識失敗)になります。DynaEye標準アプリケーションやDynaEye部品では、そのページは認識失敗になりますが、次ページの認識処理に進みます。DynaEyeコンポーネントキットでは、認識メソッドがエラー終了します。その後の処理は、アプリケーション開発次第となります。 |
| Q12 | 円記号(¥)やスラッシュ(/)などの記号が読めないことがありますが、なぜでしょうか? |
| A12 | 一部の記号は、数字や英大文字と区別するため、特殊な書き方をする必要があります。以下に書き方を示します。詳細については、ユーザーズーガイドを参照してください。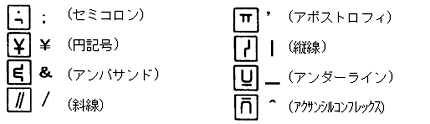 |
| Q13 | ドロップアウトカラー帳票を帳票認識すると、イメージが上下逆に回転してしまいます。 |
| A13 | 以下に該当していないか確認してください。
|
| Q14 | ドロップアウトカラー帳票を読んでいます。正しく書式定義を行なったはずですが、左右にずれて読み取られます。原因を教えてください。 |
| A14 | ドロップアウトカラー帳票の読み取りには、帳票イメージの周囲に8mm程度の黒帯(黒背景)が必要です。DynaEye proはこの黒背景から用紙の端を検出し、これをもとに読み取り位置を決めます。黒背景に白抜けがあったり、黒背景に別な黒い図形が近接していた場合、用紙の端を誤検出するため、読み取り位置がずれることがあります。 ずれた読み取り箇所の左右の黒背景が正しく出ているか、帳票のイメージデータをご確認ください。問題が無い場合、書式定義のイメージも確認ください。 用紙の端に大きいノイズが出ている、用紙の端に黒印刷がある場合には用紙端の検出に失敗します。用紙の端から2.85 mmにはドロップアウトカラー以外の印刷を行なわないようにしてください。ユーザーズガイドの「9.1 書式定義とは」の項目も参照ください。 黒背景が完全な黒ベタではなく、白抜けが発生している場合にも検出を誤ります。これは以下の原因が考えられます。
|
| Q15 | カタカナ欄で濁点付き文字に誤読することが多いのですが? |
| A15 | 濁点付き文字への誤読が多い場合、濁点/半濁点を別枠に、つまり文字枠2つに書いて頂いた方が高い認識率が得られます。この場合、書式定義のフィールド情報では以下のように字種を設定します。 |
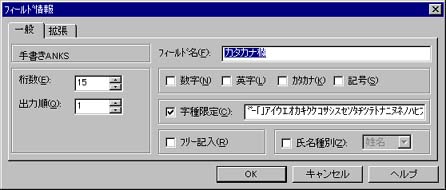
| Q16 | 問題なく運用していましたが、急に、認識できなくなったり、認識率がとても悪くなったりします。どうしてでしょうか? |
| A16 | 以下のような原因が考えられますので、ご確認をお願いします。
|
| Q17 | フリーピッチの住所欄(手書き日本語フィールド)は何行まで読めますか? |
| A17 | 手書き日本語フィールドであり、住所知識処理を設定してあり、フリーピッチ(一文字毎に枠が無い欄)の場合のみ、複数行の認識が可能です。行数の上限が決まっている訳ではありませんが、
|
| Q18 | フリーピッチの住所欄で、全く違う住所になることがあります。住所知識処理では、郵便番号と住所のどちらが優先されますか? |
| A18 | 特にどちらを優先していることはありません。また、住所の結果から郵便番号を置き換える処理はしていません。 住所知識処理の流れとしては、下記となります。
|