DynaEye 11に関して、お客様から寄せられた主なご質問とその回答を掲載しています。
DynaEye 11は、大量の紙帳票における入力業務を効率化するAI-OCRソフトウェアです。読み取り放題で利用できるオンプレミス型のため、大量処理でも安心して運用できます。申請書や伝票などの帳票に記載された文字をデータ化し、業務全体の効率化やプロセス改善につなげます。
DynaEye 11は、単に文字を読み取るだけでなく、業務プロセス全体の効率化を実現できる点が特長です。 AI-OCRは認識精度が100%ではないため、実運用では確認や修正が発生しますが、DynaEye 11では確認が必要な箇所だけをチェックできるため、確認作業の負担を大きく軽減できます。 また、読み取り放題で利用できるオンプレミス型のため、大量の紙帳票を安定して処理できる点も他製品との違いです。
DynaEye 11は、インストールしたPC内でOCR処理を行うオンプレミス型のAI-OCRです。 クラウド型AI-OCRサービスのように外部サーバーへデータを送信する必要がないため、個人情報や機密情報を扱う業務でも安心して利用できます。 また、ネットワーク環境に左右されず、アップロードやダウンロードの待ち時間も少ないため、大量の紙帳票でもスムーズに読み取りから確認作業まで進められます。
申込書や各種申請書、伝票、自社で発行している帳票など、項目名や項目の位置が一定の決まったレイアウトを持つ定型帳票の入力業務に適しています。 特に、大量の帳票を日常的に処理している業務や、手入力や確認作業に多くの時間がかかる業務で効果を発揮します。
自治体、金融、医療、BPO事業者など、大量の紙帳票を扱いながら高いセキュリティが求められる業務で多く利用されています。 その他、製造業や流通業などの幅広い業種で、定型帳票の入力や確認作業の効率化を目的に活用されています。
帳票内容によって認識精度が異なり、処理量にもよりますが、AI-OCRを活用することで入力や確認にかかる工数を大幅に削減できます(認識率80%でも約5割の削減)。 具体的な削減効果や活用イメージは、「認識精度だけでは計れない導入効果」で詳しくご紹介しています。
99.2%※の認識精度でデータ化が可能です。 手書き文字や活字、バーコードなど幅広い文字種に対応しており、さまざまな帳票の読み取りが可能です。 ※当社基準の帳票を用いた検証結果(標準アプリケーション使用時)
ただし、帳票の記入状態や文字の種類、レイアウトによって認識精度は変動するため、実際の読み取り結果については無償トライアルなどでご確認いただくことをおすすめしています。
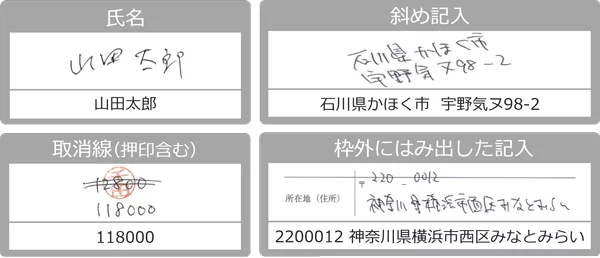
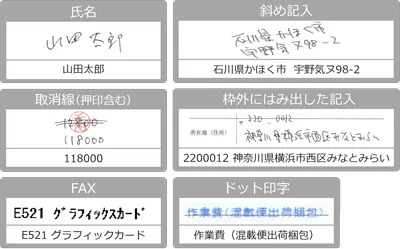
クセのある手書き文字の読み取りにも対応しています。 斜めの文字や枠外にはみ出した記入も認識でき、取消線が引かれた場合も訂正後の文字だけを読み取ることが可能です。 実際の業務で発生するさまざまな記入状態の帳票にも対応できます。
「DynaEye 11 Entry AI-OCR」は、印刷品質が低い帳票の読み取りにも対応しています。
AI-OCRをご利用いただくことで、FAX受信紙のようにノイズが多い帳票や、ドットプリンターで印字された帳票についても、従来より高い精度で読み取ることが可能です。 ただし、原稿の状態によって認識精度が異なるため、実際の読み取り結果については無償トライアルなどでご確認いただくことをおすすめしています。
※本機能はV11.0L50以降でご利用いただけます。 ※標準アプリケーションをご利用される場合、フィールドの[項目情報]で「AI type-2(手書き / 活字)」を選択してください。
DynaEye 11では、意図しない認識精度の低下(レベルダウン)を防ぐため、お客様のデータを利用して自動的に学習する仕組みは採用していません。認識精度の改善は、開発元で継続的に実施し、アップデートとして提供しています。そのため、運用中に認識精度が自動的に変化することはありません。
DynaEye 11は、非定型帳票にも対応しています。 ただし、非定型帳票はレイアウトのばらつきが大きいため、帳票によっては効率化の効果が出にくい場合があります。 非定型帳票のデータ化をご検討中の場合は、「PaperStream AI」をご検討ください。
罫線や特徴的なレイアウトがない帳票は、正しく認識できない場合があります。 また、原本と比べて画像に大きな傾き(5°以上)や拡大/縮小(±10%以上)がある場合も、認識結果に影響が出ることがあります。
導入までの期間は、帳票の種類や運用方法によって異なりますが、60日間の無償トライアルの中で、操作性や認識精度をご確認いただきながら、運用フローを整理したうえで導入いただくケースが一般的です。 また、導入支援サービスもご用意しており、用途に応じてご活用いただけます。
チュートリアル動画やスタートアップガイドをご用意しているため、専門知識がなくてもスムーズに準備を進めていただけます。 また、評価期間中は個別相談会も実施しており、導入に向けた不安や疑問についてもご相談いただけます。 無償トライアルはこちらからお申し込みいただけます。
AI-OCRの認識精度は100%ではないため、確認・修正作業は必要です。 DynaEye 11では、確認が必要な箇所のみを効率的にチェックできる機能(ベリファイOCR)により、すべてを目視で確認するのではなく、最小限の作業で確認・修正を行えます。 そのため、手入力と比べて大幅な工数削減につながります。
スキャナーは必須ではありません。 PDFや画像ファイルからの取り込みにも対応しており、複合機などで電子化したデータもご利用いただけます。 ただし、認識精度を高めるためには、元となる画像の品質が重要です。 原稿サイズや傾きを自動補正できるイメージスキャナーを活用することで、安定した読み取りが可能になります。 なお、取り込み可能な解像度やファイル形式などの条件があるため、入力仕様に応じたデータをご利用ください。
AI-OCRに適した画像を安定して生成できる、業務用イメージスキャナー「fiシリーズ」の活用もご検討ください。
認識結果はCSVやテキストなどの形式で出力できるため、既存の業務システムとの連携が可能です。 出力データを業務システムに合わせた形式に変換する機能も備えているため、さまざまな業務システムとの連携に柔軟に対応できます。
可能です。 システム組み込み用開発キット(SDK)をご利用いただくことで、自社システムにOCR機能を組み込むことができます。
また、OCR機能をSaaSサービス内に組み込むことも可能です。 インターネットを経由したデータ送受信を行うことなく、自社サービス内で処理が完結するため、セキュアでレスポンスの良いAI-OCR機能の提供に活用いただけます。 SaaS組込版ライセンスについては、こちらからお問い合わせください。
ご利用用途に応じて、最適なライセンスが異なります。
PCにインストールして単体で利用したい場合は、アプリケーション型のライセンス(Entry AI-OCR / Entry)、業務システムにOCR機能を組み込んで利用したい場合は、開発キット型のライセンス(SDK AI-OCR / SDK)をご利用ください。
また、アプリケーション型のライセンス(Entry AI-OCR / Entry)では処理枚数に応じたプラン(Lite)をご用意しています。
お客様のご利用シーンに応じた最適な構成をご検討される場合は、お気軽にお問い合わせください。
AI-OCRありのライセンスは、クセのある手書き文字にも対応し、幅広い帳票の読み取りが可能です。 また、確認が必要な箇所のみを効率的にチェックできる「ベリファイOCR」機能にも対応しています。 加えて、請求書や注文書などのようにレイアウトが多様な帳票にも対応しています。
一方、AI-OCRなしのライセンスは従来のOCR技術による読み取りとなり、申込書や届出書などの定型帳票の活字や一文字枠のある手書き文字の読み取りに適しています。
帳票の種類や記入内容に応じて、適切なライセンスをご選択ください。
「Entry AI-OCR / Entry」では、確認・修正作業を複数のPCで分担できる「マルチステーション」機能により、OCR後の作業を効率的に分散して行うことができます。 なお、マルチステーション機能をご利用いただく場合は、確認・修正作業を行うPCごとに「Entry マルチステーション」ライセンスの追加が必要となります。
「SDK AI-OCR / SDK」の場合は、用途に応じてシステム構成を設計することで、複数端末での利用に対応可能です。 また、SDKを利用して構築したシステムを運用する場合は、端末ごとにランタイムライセンスが必要となります。
DynaEye 11は、1年ごとの定額制で、機能や処理量に応じたプランを504,000円~、ご用意しています。
読み取り放題でご利用いただけるため、処理量を気にせずお使いいただけます(Liteを除く)。 また、2年目以降は継続ライセンスを低価格でご用意しており、継続してお使いいただくことで費用対効果を高められます。
アプリケーション型ライセンス(Entry)の価格はこちら、開発キット型ライセンス(SDK)の価格はこちらをご確認ください。
定額制は、あらかじめ決められた費用でご利用いただける仕組みで、処理量にかかわらず一定の費用で運用することができます。 一方、従量課金は処理したページ数や項目数に応じて費用が発生するため、処理量に応じて費用が変動します。
DynaEye 11では定額制(読み取り放題)でご利用いただけるため、処理量を気にせず運用いただけます。 (Liteの場合は上限6,000ページまで)
1年ごとの定額制のため、利用状況に応じて費用が変動したり、想定外の追加課金が発生することはありません。
現在の業務量や運用方法に応じて効果は異なりますが、現状の作業時間や人件費と比較することで費用対効果をご検討いただけます。 導入効果の試算表付き資料はこちらからダウンロードいただけます。
60日間の無償トライアルをご利用いただけます。 実際の帳票を用いて操作性や認識精度をご確認いただきながら、運用イメージの検証にもご活用いただけます。 トライアルはこちらからお申し込みください。
また、お客様に代わって帳票の読み取り性能や運用効果を検証する無償事前検証サービスもご用意しています。
導入に関するご相談は、お問い合わせフォームより承っております。
ご利用用途や運用イメージに応じた最適な構成についても、お気軽にご相談ください。
トライアル中のお客様向けに、オンライン個別相談会をご用意しております。 運用方法や設定に関する疑問点についても、製品サポート担当者が丁寧に回答いたします。
ご希望の方はこちらからお申し込みください。
DynaEye 11の各種マニュアル(運用管理ガイド/開発ガイド)は、無償評価版や製品媒体のインストーラーに収録されています。 無償評価版を入手することで、導入前にも内容をご確認いただけます。
なお、紙のマニュアル(製本マニュアル)は提供しておりません。
はい、使えます。
[手順]
標準アプリケーションの場合 「キャビネットの移出入」機能を使用すれば、キャビネット上の書式定義、イメージデータ、認識結果、連携定義データ、スキャナ定義データ、認識結果出力定義データを全て新しいPCに移行することができます。 手順の詳細は、「DynaEye 11 Entry 標準アプリケーション 運用管理ガイド」をご参照ください。
エントリーアプリケーションの場合 「資源のエクスポート」「資源のインポート」を使用すれば、プロファイルと学習データを含む項目定義を新しいPCに移行することができます。 手順の詳細は、「DynaEye 11 Entry エントリーアプリケーション 運用管理ガイド」をご参照ください。
帳票のサイズや処理枚数などを踏まえ、必要な性能に応じて選定してください。 また、ドロップアウトカラー帳票の読み取りやナンバリング機能など、特定のスキャナーに対応した機能もあるため、用途に応じた選定が重要です。
スキャナー選定に迷われる場合は、スキャナーセレクトナビをご活用いただくか、お問い合わせフォームよりお気軽にご相談ください。
DynaEye 11を使って、Fax-OCRシステムを構築するには十分な注意が必要となるため、専用のFax-OCRシステムをおすすめします。 DynaEye 11には、Faxを直接受信する機能はありません。別途、Fax受信機能を用意する必要があります。その他にも以下に示す注意が必要です。
DynaEye 11は帳票読み取り専用のAI-OCRソフトウェアです。 そのため、申請書や伝票などの帳票に記載された文字の読み取りに適しています。
活字の読み取りにも対応していますが、雑誌やレポートなどの一般的な文書を読み取る用途には適していません。 また、罫線や特徴的なレイアウトがない帳票は、正しく認識できない場合があります。
一文字ごとの区切りがない記入欄(フリー記入 / フリーピッチ欄)の読み取りにも対応しています。 対応ライセンス:Entry AI-OCR / Entry Lite AI-OCR / SDK AI-OCR
備考欄やメモ欄のように、帳票内の自由記入欄に記載された手書きの内容であれば認識可能です。 ただし、罫線や特徴的なレイアウトがない帳票の場合(無地の紙に自由に記入されたメモなど)は、正しく認識できない場合があります。
縦書きには対応しておりませんが、縦に1桁づつ文字枠を並べた帳票を設計すれば、読み取り可能です。ただし、縦書き用の文字は読み取りできません(カッコ、長音など)。
DynaEye 11にはタイミングマークを検出する機能がないため、マークシート(OMR専用用紙、ドロップアウトカラー帳票)を処理することはできません。
標準アプリケーション(定型)にはマーク読み取り機能がありますが、OMR専用用紙を読もうとすると、
などの理由により、処理できません。
ただし、以下の条件を満たすように帳票設計すれば、ドロップアウトカラー帳票、非ドロップアウトカラー帳票に関わらず、マークフィールドとして読み取ることができます。また、この場合、マークの形状は問いません。
別途インターネット接続可能なPCを準備いただき、代理で認証手続きを行うことでアクティベーションが可能です。 操作としては、インターネット接続可能なPCから認証サイトで代理認証後、認証済みファイルを保存して対象PCへインポートしていただくことになります。
0.5mm程度・HBのシャープペンシルや一般的なボールペンは、安定した読み取りが可能です。 一方で、線が極端に薄い・細い場合や、にじみ・かすれがある場合、太いマーカーや柔らかい芯の鉛筆などは、認識精度に影響が出る場合があります。
実際の帳票での読み取り結果については、事前の検証でご確認いただくことをおすすめしています。
スキャナー入力したとき、網掛け部分は画像が安定しないため、DynaEye 11の帳票認識に悪影響が出ます。網掛けは避けてください。
OCR専用用紙のような点線の記入ガイドを印刷することはおすすめしていません。
ドロップアウトカラー帳票として、読み取り時に消去される色で印刷する場合は問題ありませんが、黒などの濃い色で印刷された場合は、認識の妨げになる可能性があります。 DynaEye 11では、帳票に印刷された枠や罫線などを消去し、文字だけを抽出して認識します。 そのため、点線の記入ガイドを印刷すると、そのガイドを消去する際に、上に書かれた文字の一部も欠けてしまい、正しく認識できない場合があります。これは数字記入欄だけでなく、マーク欄の点線ガイドなどでも同様です。 記入ガイドを印刷しなくても十分な認識精度が得られるため、使用しないことを推奨しています。
帳票IDフィールドは、その他の一般のフィールドと同じように読取り可能範囲内であれば、どこにあっても構いません。
なお、帳票IDの認識方式が帳票エッジ方式の場合は、混在して読み取るすべての帳票種類において、帳票IDフィールドの位置は同一である必要があります。基準マーク方式の場合は、異なっていても読み取りできます。
アンカーパターンと位置決め用マークは、定型帳票の書式定義時に設定する位置決め機能で、帳票リジェクト(帳票認識するとイメージに×が付いてまったく読み取れないもの)を防ぐためのものです。
通常はどちらも指定なしで読み取れますが、帳票上に特徴の少ないものは、アンカーパターンを指定しないと読めないものもあります。なお、アンカーパターンと位置決めマークとも、文字の認識精度を向上させるものではありません。 アンカーパターンと位置決め用マークには、以下のような特徴と用途があります。
アンカーパターン 帳票の位置決めのために、帳票上のユニーク、かつ、安定したプレ印刷を設定します。 ここで、ユニークとは類似の形状が近くにないことであり、安定したとは、比較的太く (スキャナーの入力濃度によって影響されにくい)、かつ当該部分およびその周囲に文字などが記入されない部分です。例えばロゴやタイトル文字、大きいポイントの文字などがこれに該当します。 アンカーパターンは書式定義中に自動抽出されますので、通常は利用者が設定する必要はありません。しかしながら、自動抽出に失敗するケースもあります。 そのような場合のために、手動でアンカーパターンを設定する機能を備えています。
位置決め用マーク 位置決めに適したアンカーパターンが存在しない帳票の場合、位置決め用マークを帳票四隅に印刷することで、 アンカーパターンの代用をさせることができます。位置決め用マークは、DynaEye 11が誤らないように、形状や周囲の空白等に条件を決めています。 そのため、アンカーパターンより検出精度は高くなっています。 アンカーパターンの手動設定はあくまで補助的な機能であり、もし書式定義できない帳票の場合、 本来は帳票レイアウトの変更か、位置決めマークの印刷が必要となります。
以上をまとめると、次のようになります。
DynaEye 11 Entryでは、fiシリーズ イメージスキャナーのみの対応となります。サポート機種については、「動作環境」をご確認ください。
DynaEye 11 SDK、および、DynaEye 11 ランタイムでは、32ビットTWAINドライバがあれば他社製スキャナーや複合機も接続可能です。 なお、複合機をスキャナー代わりに使用している場合、既定でディザやハーフトーンのモードが選択されている場合があります。これらはDynaEye 11の読み取りでは使用できない画像ですのでご注意ください。お使いの機器の説明書で確認してください。
ネットワークスキャナーの使用はサポート対象外です。
ScanSnapにはTWAINドライバが無いため使用できません。
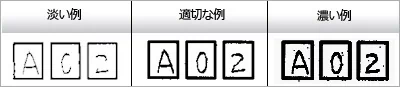
二値白黒でスキャンする場合、入力濃度によって文字の認識精度は大きく影響を受けますので、濃度設定には注意が必要です。しかしながら、濃度設定はお使いのスキャナーやスキャナードライバによって異なりますので、一概に「これこれの濃度で」と申し上げることはできません。読み取りたい用紙に実際に記入したものを用意し、設定を変えながら何度か入力して、線が切れたりかすれたりすることなく、また細かいところがつぶれないような適当な設定を見つけるようにしてください。 例えば、fiシリーズイメージスキャナーの場合、スレッシュホールドを150から180程度の間で調整することが多いようです。
白黒イメージでも帳票認識を行うことができるのは白黒(単純)二値画像だけです。 画像に点々を並べることで擬似的に濃淡を表すモード(ディザやハーフトーン)の画像はDynaEye 11では扱えません。 なお、白黒二値といっても、TWAINドライバによって表記が異なりますので、注意してください。 適当な選択肢(例):「二値白黒」(fiシリーズ イメージスキャナー)
基準マークのないドロップアウトカラー帳票の場合、原則としてB4サイズまでの対応となります。
これは、帳票の位置決めを行うために、イメージ上に一定幅の黒背景(黒色の縁)が必要となるためです。 スキャナー機種によっては、A3対応機種であっても十分な黒背景が確保できない場合があります。
一方で、fiシリーズのイメージスキャナーを使用し、適切な設定・運用を行うことで、A3サイズのドロップアウトカラー帳票を読み取ることも可能です。
詳細な条件については、「標準アプリケーション 運用管理ガイド」または「開発ガイド(書式認識編)」をご参照ください。 ※エントリーアプリケーションはドロップアウトカラー帳票に対応していません。
DynaEye 11 標準アプリケーションのスキャナ定義画面で、A4判、200dpi、フルカラー、黒背景あり、カラー保存用画像品質4の場合、1ページあたり 約1MB となります。高圧縮にするとノイズが目立ち、文字認識に悪影響を及ぼしますので、カラー保存用画像品質は4以上を推奨します。
DynaEye 11では、マルチフィード検出の設定はできません。 TWAIN ドライバにマルチフィード検出の設定を行うことで、読み取りを中止することが可能です。
できません。最初に設定した値(文字列+末尾 5桁の数字。ただし、コンポーネントキットでは、5桁または8桁)の数字部分を DYNA00001, DYNA00002 のように1枚ずつ自動的にカウントアップして印字を行ないます。
90度単位にどの方向を向いていても、帳票認識の際に補正を行ないますので処理可能です。 ただし、基準マークのないドロップアウトカラー帳票は補正ができません。あらかじめ向きを揃えて入力してください。
fiシリーズイメージスキャナーをお使いの場合は、標準アプリケーションの定義画面を起動し、「スキャナ定義」画面、または、エントリーアプリケーションの「プロファイル設定」画面「入力設定」タブより回転を指定できます。 DynaEyeコンポーネントキットのスキャナコントロールをご使用の場合は、Rotationプロパティを使っても同様に回転できます。どちらの場合も、表面と裏面の回転方向を180度変えることが可能です。合わせて「スキャナーから読み込んだイメージが、上下さかさまや90度回転など、意図しない向きに回転してしまいます。」もご覧ください。
以下に該当しないか確認ください。
【補足】基準マークの無いドロップアウトカラー帳票以外では、帳票認識が成功すると、帳票イメージを正しい方向に回転します。帳票認識に失敗した場合はイメージを回転しないため、認識に失敗したものだけ、向きが異常に見える場合があります。
WIAドライバによるスキャナ読取りを行っていませんか? WIAドライバはMicrosoftより提供されていますが、DynaEye 11 はWIAドライバによるスキャナ読取りをサポートしていません。「ファイル」メニューから「スキャナ選択」を実行し、表示されたダイアログで「WIA-(スキャナー名)」が表示されていたら、「WIA-」のついていないドライバを選択するようにしてください。
fiシリーズ イメージスキャナーを利用する場合は、TWAIN画面を表示せずにスキャナ読取りを行うことができます。
DynaEye 11 標準アプリケーション 定義画面の「ファイル」メニューから「スキャナ定義」を選択し、「TWAIN画面を表示する」のチェックマークを外すと、「スキャナ定義」ダイアログで設定した条件で、(TWAIN画面を設定することなく)読み取りを行うことができます。
DynaEye 11 エントリーアプリケーション TWAIN画面は表示されません。
DynaEyeコンポーネントキット(スキャナコントロール) あらかじめスキャナコントロールのプロパティに設定した条件で、読み取りを行うことができます。TWAIN画面の表示・非表示は、メソッドの引数で指定します。
DynaEye部品(スキャナ読取り部品) あらかじめパラメーターファイルに設定した条件で、読み取りを行うことができます。TWAIN画面の表示・非表示もパラメーターファイルで指定します。
TWAIN画面に、以下のような設定をしている場合、DynaEye 11の「スキャナ定義」ダイアログボックスの設定よりも優先して使用されます。
DynaEye 11の設定で読み取りをおこなう場合は、上記の機能を使用しないでください。
fiシリーズイメージスキャナーをお使いの場合、ブランクページスキップ機能により白紙を除去することが可能です。TWAIN画面を開いて設定してください。 標準アプリケーションの場合、定義画面を実行して「スキャナ定義」の「TWAIN画面を表示する」にチェックを入れることにより、読み取り実行時にTWAIN画面が表示されます。一度設定しておくと、TWAIN画面を表示しない読み取りのときも、ブランクページスキップが有効になります。 エントリーアプリケーションの場合、「プロファイル設定」画面「入力設定」タブからブランクページスキップ機能を設定したPaperStream IPのプロファイルを指定して読み取ることができます。 DynaEyeコンポーネントキットのスキャナコントロールをお使いの場合には、SkipWhitePage プロパティを使うこともできます。
DynaEye 11 標準アプリケーション / エントリーアプリケーション / DynaEye部品ではサポートしておりません。 コンポーネントキットを利用した場合には、TWAIN画面を表示して同時出力(マルチイメージ)を設定することで使用可能です。アプリケーションを作成することによって、2値画像を認識に使用し、カラー画像を保管する、といったことができます。 ただし、TWAIN画面非表示での動作はサポートしていません。
DynaEye 11は、マルチイメージに対応していません。 TWAINドライバやPaperStream IP(TWAIN)ドライバの画面で、マルチイメージが設定されている場合に、画像タイプと異なったり、スキャン後の動作が異常となる場合があります。 「マルチイメージ有効」のチェックを外す、または「マルチイメージ」を選択しないでください。
PaperStream IPドライバの「現在の設定」プロファイルにて、以下のいずれかの設定をしている場合、DynaEye 11の「スキャナ定義」ダイアログボックスの設定よりも優先されるため「明るさ」「コントラスト」の設定が無効となります。
DynaEye 11の設定で読み取りを行う場合は、上記の機能を使用しないでください。
一つのキャビネットに複数の書式定義を作成して、入力された用紙の様式に合わせて自動的に書式定義を選択して帳票認識を行うことができます。これを異種帳票処理と呼びます。 印刷された罫線パターンや色情報などをもとに帳票を識別する「識別帳票レイアウト識別」と、あらかじめ印字されたIDをもとに帳票を識別する「帳票ID識別」の方式があります。
DynaEye 11 標準アプリケーションの定義画面で、作成した書式定義を選択して、[ファイル]メニューから[名前を付けて保存]を実行し、ファイルの種類を「書式定義情報(*.DDF)」にして、保存してください。そのファイルを他のPCに持っていって、[ファイル]メニューから[開く]を実行して、取り込んでください。
DynaEyeのバージョンが違っていませんか。DynaEyeのバージョンが、書式定義を作成したPCのDynaEyeよりも古いと、その書式定義を開くことはできません。 逆に、書式定義を作成したバージョンよりも新しいバージョンのDynaEyeであればその書式定義を使用することができます。 ただし、この場合は新しいバージョンのDynaEyeで書式定義の更新(一旦、書式定義で開いて上書き保存)を行なってください。
ドロップアウトカラー帳票(OCR専用帳票)の書式定義の作成の仕方は、「標準アプリケーション 運用管理ガイド」または「開発ガイド(書式認識編)」を参考にしてください。なお、ドロップアウトカラー帳票の読み取りに関しては、特定のスキャナーが必要となりますので、ご注意ください。
該当の書式定義を開き、ナビゲーションバー[帳票定義]から[帳票設定]領域の詳細設定ボタンを選択し、「ドロップアウトカラー帳票」をチェックしてください。
帳票ID方式による異種帳票処理の場合、データ編集前の認識結果が帳票IDとみなされます。データ編集後ではありません。 従って、IDフィールドが空白だったときにデータ編集によりゼロ補充を行なって00のIDと見なす、などはできません。
手書きと活字が混在するフィールドの[項目情報]で「AI type-2(手書き / 活字)」を選択してください。 「AI type-2(手書き/ 活字)」では手書き文字を高精度に認識できない場合は、「AI type-1(手書き特化)」を選択してください。
可能です。イメージフィールドは、任意の文字フィールド(またはマークフィールド)を包含したり(されたり)、部分的に重なるような定義が可能です。勿論、イメージフィールド同士も同様です。
書式定義が可能なイメージは解像度が、200dpi、240dpi、300dpi、400dpiのいずれかでなければなりません。デスクトップ画面で縮小イメージをマウスで右クリックして、プロパティを表示させて「データ情報」の「dpi」の項を確認してください。上記以外の解像度で読み込んでいる場合は、適切な解像度で再度イメージを読み込んでください。 お使いのスキャナードライバによっては、解像度が正しく設定されないものがあります。このような場合は、スキャナーのメーカーまでお問い合わせください。
DynaEye 11では、ひとつのキャビネットで複数の書式を混在させて処理する異種帳票処理が可能ですが、混在可能な書式は一定の条件を満している必要があります。ご指摘のメッセージ『書式定義に矛盾があります。』は、この条件が満足されないときに表示されます。
活字として設定しているのに認識結果がすべて空白になる場合、書式定義に使用した帳票イメージが原因の可能性があります。
DynaEye 11では、帳票に印刷された文字や罫線などを消去してから文字認識を行います。 そのため、書式定義に使った帳票イメージに文字が印字された状態だと、その文字も罫線と同様に帳票のプレ印刷として扱われ、認識前に消去されてしまうため、認識結果が空白になることがあります。
対処方法としては、書式定義を行う際に、文字が印字されていない帳票イメージ(未記入の帳票)を使用してください。 やむを得ず文字が印字された帳票を使用する場合は、書式定義画面の「範囲内消去」機能を使用して、該当部分の文字を削除してください。
「数字」「英字」などのカテゴリごとの選択と、字種限定欄に1文字ずつの設定とを両方行なった場合、どちらかの条件に合致した文字を読み取ります。例えば、「数字」にチェックした上で字種限定欄に「0123」と設定しても、0から9までのすべての数字を読み取ります。「数字」のチェックを外せば、0123に限定されます。
NW7、CODE39、CODE128、ITF、JANが読み取り可能です。
QRコードの読み取りが可能です。詳細な仕様は「標準アプリケーション 運用管理ガイド」または「開発ガイド(書式認識編)」をご確認ください。 ※QRコードは株式会社デンソーウェーブの登録商標です。
フリーピッチの住所欄(文字枠のない記入欄)は、最大で5行まで読み取ることが可能です。
ただし、以下の条件を満たす必要があります。
特にどちらを優先していることはありません。また、住所の結果から郵便番号を置き換える処理はしていません。 住所知識処理の流れとしては、以下となります。
一文字枠の無いフリーピッチの場合は、乱雑に書かれたり、小さな文字を書かれたりする場合があり、住所知識処理を使っても文字認識できない場合があることをご承知おきください。
以下のような原因が考えられますので、ご確認をお願いします。
DynaEye 11では、書式定義に使用したひな型の解像度と、その書式定義を使って帳票認識を行う帳票の解像度は一致している必要があります。 なお、書式定義の解像度を変えることはできません。ひな型となるイメージをスキャンし直す必要があります。
モノクロ形式でも、画像の階調を表現するために、中間調処理やディザ処理を行うことができるスキャナーがあります。DynaEye 11の帳票認識では階調表現をしたイメージを扱うことはできません。スキャナーの設定で、「中間調」「ディザ」「ハーフトーン」といった指定(お使いのスキャナーによって異なります)は行なわないでください。
エラーとなった画像の縮小イメージを右クリックすると、「表示ページプロパティ」が表示されます。認識の項目で""の右側にある8桁の英数字が認識失敗のエラーコードです。プロパティのヘルプボタンをクリックし、[エラーメッセージ]-[エラーコード]-[認識エラーコードの詳細]の項目を開いて、原因の詳細をご確認ください。 よくある原因の一つに帳票照合の失敗(E2032441 など、下4桁が2441)がありますが、この場合、大きく分けると二種類の原因が考えられます。
前者に関しては、
などが考えられます。これらは適切な設定を行うことで、読み取り可能です。 後者に関しては、
などが考えられます。こちらは、DynaEye 11の読み取り対象とするのが難しい書式です。帳票のデザインを再検討してください。
手動でアンカーパターンを指定する場合、繰り返し同じようなパターンが出現する部分を設定していませんか?例えば、「住所・氏名」という文字の上にアンカーを設定していて、そのすぐ下に同じ文字があるようなケースです。DynaEye 11は帳票認識の際に用紙の歪みを吸収する関係上、同じパターンがすぐ近くにあると誤る可能性があります。アンカーパターンを設定する場合は、類似したパターンがない場所を選んでください。
書式定義にないIDの帳票を認識した時はエラー(認識失敗)になります。DynaEye 11 標準アプリケーションやDynaEye 部品では、そのページは認識失敗になりますが、次ページの認識処理に進みます。DynaEye コンポーネントキットでは、認識メソッドがエラー終了します。その後の処理は、アプリケーションの開発次第となります。
スキャナーで入力するときに黒背景をつけることで、帳票IDを認識するときには黒背景を基準に、帳票内部を認識するときにはプレ印刷を基準にして認識処理を行うことが可能です。 このとき、書式定義の帳票情報の設定では次のように指定してください。
ただし、以下の点にご注意ください。
以下に該当していないか確認してください。
ドロップアウトカラー帳票の読み取りには、帳票イメージの周囲に8mm程度の黒帯(黒背景)が必要です。DynaEye 11はこの黒背景から用紙の端を検出し、これをもとに読み取り位置を決めます。黒背景に白抜けがあったり、黒背景に別な黒い図形が近接していた場合、用紙の端を誤検出するため、読み取り位置がずれることがあります。 ずれた読み取り箇所の左右の黒背景が正しく出ているか、帳票のイメージデータをご確認ください。問題が無い場合、書式定義のイメージも確認ください。 用紙の端に大きいノイズが出ている、用紙の端に黒印刷がある場合には用紙端の検出に失敗します。用紙の端から2.85 mmにはドロップアウトカラー以外の印刷を行なわないようにしてください。 黒背景が完全な黒ベタではなく、白抜けが発生している場合にも検出を誤ります。これは以下の原因が考えられます。
はい、項目の内容に応じたデータチェックが可能です。 データチェック機能を使うことで、認識結果の内容が正しいかどうかを、設定したルールに基づいて確認できます。 また、複数の項目を組み合わせたチェックも行えます。
例えば、
などの設定が可能です。
帳票イメージを編集用のウィンドウとは別のウィンドウとして表示している場合、終了時に帳票イメージのウィンドウの位置やサイズを記憶して、次に修正画面を立ち上げると前回と同じ位置・サイズでウィンドウが表示されます。そのため、ウィンドウの位置やサイズを変更したり、画面設定を変更したりすると見えなくなってしまうことがあります。 以下のケースに該当しないかご確認ください。
認識注意文字(リジェクト)文字間でカーソルを移動するには、タブ[Tab]キーを押すことで次の認識注意文字にカーソル移動します。また、シフト[shift]+タブ[Tab]キーを押すと、直前の認識注意文字にカーソル移動します。 (認識注意文字以外にも、論理エラー、画面入力項目へもタブ[Tab]キーで移動します。)
修正画面において、イメージ参照入力機能により、当該イメージを参照しながらキーボードからデータ入力をすることができ、そのデータを保存・出力することができます。イメージ参照入力を行なわなければ、そのページのデータは出力されません。
可能です。マークの選択肢毎に任意の出力コードを設定することができます。書式定義を作成するときに、設定したいマークフィールドの[項目情報]で、それぞれの読取領域に対して、出力文字(1文字、漢字も可)を設定してください。
DynaEye 11は、認識データをCSV形式で出力する際に、ダブルクォテーションで囲むかどうかを選択することが可能です。ダブルクォテーションで囲みたくない場合は、以下のように設定してください。
標準アプリケーション 出力定義ダイアログの「ダブルクォテーションで囲まない」チェックボックスをONにする。
エントリーアプリケーション 「プロファイル設定」画面の「出力ファイル設定」タブから、「ダブルクォテーションで囲む」のチェックをOFFにする。
API(部品、コンポーネントキット)でアプリケーションを作成する場合も、ダブルクォテーションで囲むかどうかを選択することが可能です。詳細はユーザーズガイド、DynaEye APIヘルプを参照してください。
標準アプリケーションでは、認識結果のイメージフィールドに該当するフィールドに、切り出しイメージデータのファイル名が出力されます。出力順は、書式定義で指定した「出力順」と同じです。なお、このファイル名には、パス名は含まれません(イメージデータは、テキストデータと同一フォルダに出力されます)。
書式定義でイメージフィールドを設定してください。文字認識フィールドの部分イメージを切り出すには、そのフィールドにイメージフィールドを重ねて設定してください。
切出しイメージ部分イメージを出力するには、認識データ出力定義ダイアログボックスの「イメージ出力」のチェックボックスをONにしてください。
DynaEye 11では、切出しイメージや全面イメージのファイル名を次のように指定することができます。
DynaEye 11 標準アプリケーション / DynaEye部品
なお、イメージはPDF / BMP / TIFF(シングルページTIFF) / JPEG / PNGでの出力が可能です。
帳票の両面の読み取りをおこなった場合、出力イメージファイルには、 1枚目の表、1枚目の裏、2枚目の表、2枚目の裏、... という順番で出力されます。1枚の帳票の表と裏は、別々の用紙として認識されます。 DynaEye 11には、表と裏の両面を一続きのデータとして管理する機能は無いため、以下の方法で対応していただくようお願いします。
ACCESS形式でデータ出力する場合には Microsoft® Access® 自体の制限であるフィールド数255を超えて出力することはできません。 出力するフィールド数を変えられない場合は、CSVまたはTEXT形式での出力をご検討ください。
DynaEye 11では、複数のPCで同じデータを同時に共有して編集することはできません。 ただし、帳票データ(イメージ・認識結果)や定義情報はファイルとして保存できるため、ファイルをコピーすることで別のPCに移行して利用することは可能です。 また、標準アプリケーションでは、マルチステーション機能(オプション)を利用することで、複数のPCで確認・修正作業を分担して行うことができます。
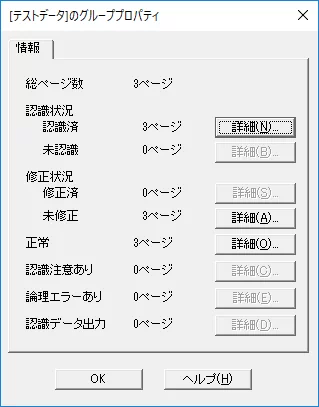
デスクトップ画面で、イメージのサムネイル上でマウスの右ボタンをクリックすると、イメージのプロパティが表示されます。表示ページのプロパティですので、見たいイメージまでページを送ってからクリックしてください。
デスクトップ画面で、認識後のイメージのタイトル上でマウスの右ボタンをクリックすると、そのグループのプロパティが表示されます。 その中の詳細をクリックすると、ページが表示されます。
スキャナ読取り部品の実行時に、任意のパス名およびファイル名を指定します。
設定ファイルにて、両面読み取りか片面読み取りかを指定できます。
帳票認識部品には、書式定義と同じ向きに入力イメージを置き換えるオプションがあります。置き換えたくない場合は、設定ファイルの"intifmode"を変更してください。
設定により、CSVの各レコードにTIFFファイル名とそのページ番号を格納することができます。
CSV形式、およびACCESS2000形式の出力に対応しています。データ出力部品は、TEXT形式の出力にも対応しています。 また、出力先のファイル名は、部品実行時の引数として任意のものが使用できます。
可能です。設定ファイルで指定します。
可能です。DynaEye部品では、例えば、マシンAで認識した結果をサーバーに保存し、マシンBからその結果を修正するというような運用も可能です。ただし、複数マシンからの同時修正はできません。
DynaEye 11のインストールフォルダにあるDynaEye APIヘルプ(DynaKit.chm)に各コントロールの仕様が記述されています。
Visual Basic® ディストリビューションウィザードは、サポートファイルのディレクトリに、Cabファイルを作成するためにプロジェクト名.DDFというファイル名でDiamond Directives Fileを作成します。従って、書式定義名がプロジェクト名と同一の場合、書式定義ファイルが上書きされてしまうことになります。書式定義名はプロジェクト名と異なる名称に設定してください。
ご使用になれません。なお、DynaEye部品であればEXE形式のため、Shell関数により起動することが可能です。
プロジェクトのプロパティにあるXP Visual スタイルを有効にしていると文字が欠ける場合があります。無効にして使用してください。
MaxLengthプロパティを設定している場合で、挿入モードになっているとMaxLengthプロパティで指定した文字数に達すると、文字の追加ができなくなります。 これは文字修正コントロールの正常な動作です。アプリケーション設計にあたってはMaxLengthプロパティを設定することが妥当か、設定する値が妥当かをご検討ください。実行時にあたっては挿入モードか上書きモードかを確認してください。
イメージ表示コントロールで画像が表示されなくなる前に何か他のアプリケーションをアンインストールしたということはないでしょうか。 そのアプリケーションが、DynaEye 11でも使用している共有ファイルをアンインストールしてしまった可能性があります。 DynaEye 11をいったんアンインストールし、再度、インストールしてください。
なお、再インストールの際には、インストール時の選択で、
を選択すれば、これまでのデータは保持されます。
書式定義において、各選択肢の「出力文字」として定義された文字が、「出力順」として定義された順番に、マークが記入された項目のみ出力されます。 例えば、
というマークフィールドに対して(マーク区切り文字MarkDelimiterを空白とした場合)、
「緑」にマーク、他の2つはマークしない場合は、"G"が出力されます。 「赤」と「青」にマーク、「緑」はマークしない場合は、"RB"が出力されます。 マークが記入されていない選択肢に対して、空白文字は出力されないので注意してください。
DynaEye 書式認識ライブラリの画像操作APIにより、マルチページTIFFファイルから任意の1ページを取り出すことが可能です。詳細は DynaEye APIヘルプにあるDynaEye書式認識ライブラリの画像操作APIに関する項目を参照ください。
DynaEyeコンポーネントキットを使うアプリケーションを開発して、DDF形式の書式定義を文字認識コントロールのSetFormatメソッドに渡す場合に、テンポラリフォルダ(TEMP)に一時ファイル(*.pin,*.ndf, *.dinなど)が作成されます。 ただし、これらの一時ファイルは文字認識コント ロールのTerminateメソッドを実行したときに自動的に削除されます。 一時ファイルが残るということは、Terminateメソッドを実行していないか、もしくはTerminateメソッドを実行せずにSetFormatを繰り返し実行しているということはないでしょうか。 上記に該当しないかアプリケーションの処理シーケンスのご確認をお願いします。文字認識コントロールのメソッドの呼び出しシーケンスについては、DynaEye APIヘルプ(DynaKit.chm)の「メソッド一覧(文字認識コントロール)」をご覧ください。
標準アプリケーションの書式定義にてイメージフィールドに指定すれば、その部分をイメージファイルとして出力することができます。また、出力の設定により全面イメージを出力することができます。そうすることで、帳票イメージをファイルに出力することができます。そのファイルをイメージファイリング等に利用してください。
できます。日付データを加えるには、標準アプリケーションの書式定義にて、出力専用項目を設定してください。日付や固定文字列を設定できます。
可能です。書式定義の設定により、ある項目の後に改行を挿入することができます。各行の最後の項目の後に改行の出力を設定してください。 また、出力専用項目を作成することで、ある項目の認識結果を何度も出力することが可能です。例えば、伝票番号のように帳票に一カ所しか記載されていない読み取り項目を各明細行の先頭に出力したい場合などに便利です。
可能です。DynaEye 11の読み取り対象になっている文字で構成されている単語であれば、知識辞書に登録することができます。従って、読み(カナ)には、数字・英大文字・カタカナ・記号、漢字には、読み取り対象字種を設定することが可能です。
知識辞書編集での登録には以下の制約があります。 これらの制約に抵触していないかご確認ください。
もし、「1. 読みのない単語のみ」を255を超えて登録したい場合には、仮の読みをつけて登録してください。ただし、3の制約に掛からないように注意する必要があります。 同様に、「2. 単語のない読みのみ」の項目については、4の制約に注意して登録をしてください。
以下を確認ください。
なおデータベースファイルが極端に大きくなった場合、2の操作が失敗することがあります。この時は新規にキャビネットを作成し、そちらにデータを移動して以後は新しいキャビネットで使用してください。
データ出力を行うには、キャビネットの空きディスク容量としてデータベースの約2倍の空き容量が必要です。空き容量が不足している場合は、キャビネットのドライブから不要なファイルを削除して、必要なディスク容量を確保してください。
DynaEye 11 標準アプリケーションの運用画面で、アイコンを表示させるためには、最初に以下の操作が必要です。
お問い合わせ